DeepSeek V4 offiziell gestartet, offizielle API-Preise angekündigt
Schlüsselwörter: deepseek v4, DeepSeek offizielle Website, DeepSeek Tutorial, DeepSeek V4 Preis
Veröffentlichungsdatum: 25. April 2026
Autor: DeepSeek HK
Heute hat DeepSeek offiziell den API-Preisplan für die neuen Modelle der V4-Serie angekündigt, was die offizielle kommerzielle Markteinführung dieses hoch erwarteten großen Modells der nächsten Generation für Entwickler weltweit markiert. Die DeepSeek V4-Serie umfasst zwei Versionen: Flash und Pro, beide unterstützen einen ultralangen Kontext von 1 Million Token. Bei stark verbessertem Leistungsniveau wurde gleichzeitig die Kosteneffizienz optimiert, was eine wettbewerbsfähigere Option für die Entwicklung von KI-Anwendungen bietet.
Modell- und Preisbeschreibung
Die API-Preise von DeepSeek werden pro Million Token berechnet. Ein Token ist die kleinste Texteinheit, die vom Modell erkannt wird und kann ein Wort, eine Zahl oder sogar ein Satzzeichen sein. Die Gebühren werden basierend auf der Gesamtzahl der tatsächlich vom Modell verarbeiteten Eingabe- und Ausgabetoken berechnet.
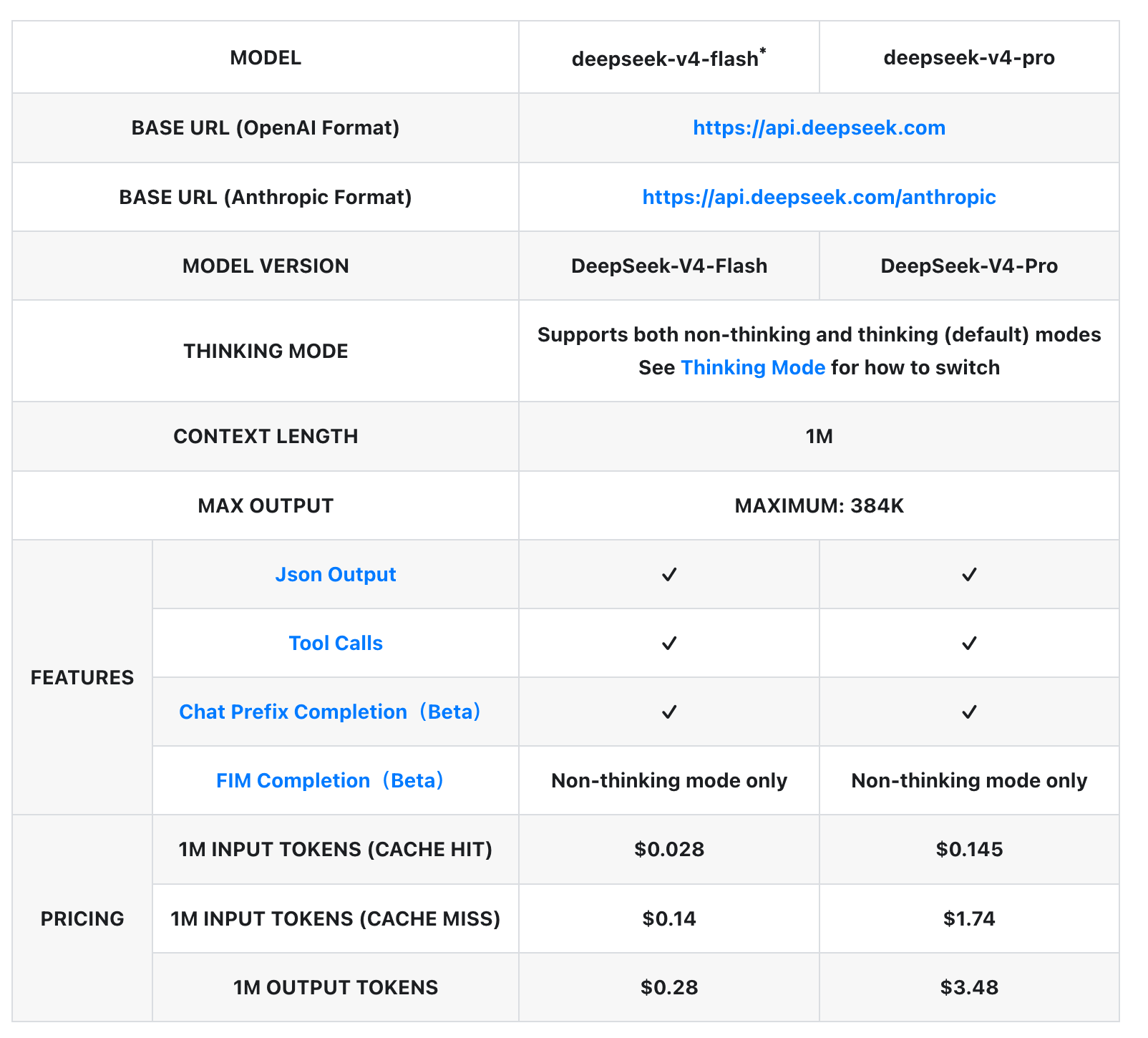
Detaillierter Vergleich der Modellparameter
| Merkmal | deepseek-v4-flash* | deepseek-v4-pro |
|---|---|---|
| Basis-URL (OpenAI-Format) | https://api.deepseek.com | https://api.deepseek.com |
| Basis-URL (Anthropic-Format) | https://api.deepseek.com/anthropic | https://api.deepseek.com/anthropic |
| Modellversion | DeepSeek-V4-Flash | DeepSeek-V4-Pro |
| Denkmodus | Unterstützt sowohl Nicht-Denk- als auch Denkmodus (Standard). Siehe Denkmodus für Umschaltanweisungen | Unterstützt sowohl Nicht-Denk- als auch Denkmodus (Standard). Siehe Denkmodus für Umschaltanweisungen |
| Kontextlänge | 1 Million | 1 Million |
| Maximale Ausgabelänge | Bis zu 384.000 | Bis zu 384.000 |
| JSON-Ausgabe | ✓ | ✓ |
| Tool-Aufrufe | ✓ | ✓ |
| Chat-Präfix-Vervollständigung (Beta) | ✓ | ✓ |
| FIM-Vervollständigung (Beta) | Nur Nicht-Denkmodus | Nur Nicht-Denkmodus |
| 1 Million Eingabetoken (Cache-Treffer) | 0,028 $ | 0,145 $ |
| 1 Million Eingabetoken (Cache-Fehler) | 0,14 $ | 1,74 $ |
| 1 Million Ausgabetoken | 0,28 $ | 3,48 $ |
- Hinweis: Die Modellnamen “deepseek-chat” und “deepseek-reasoner” werden in Zukunft schrittweise abgeschafft. Aus Kompatibilitätsgründen entsprechen diese beiden Namen derzeit dem Nicht-Denkmodus bzw. dem Denkmodus von “deepseek-v4-flash”.
Regeln zur Gebührenabzug
Tatsächlicher Verbrauchsbetrag = Token-Nutzung × entsprechender Einheitspreis. Die Gebühren werden direkt von Ihrem Aufladeguthaben oder Geschenkguthaben abgezogen. Wenn beide Guthaben vorhanden sind, verwendet das System zuerst das Geschenkguthaben.
Die Produktpreise können je nach Marktbedingungen angepasst werden, und DeepSeek behält sich das endgültige Recht zur Preisanpassung vor. Entwicklern wird empfohlen, entsprechend den tatsächlichen Nutzungsanforderungen aufzuladen und regelmäßig die offizielle Preisseite auf die neuesten Informationen zu überprüfen.
Analyse der Kernvorteile
Während die hohe Leistung beibehalten wird, wendet die DeepSeek V4-Serie eine äußerst wettbewerbsfähige Preisstrategie an, die besonders für verschiedene KI-Anwendungsszenarien geeignet ist:
Kostengünstige Rechenleistungsoption
Die Version deepseek-v4-flash bietet hervorragende Leistung zu einem extrem niedrigen Preis und eignet sich besonders für Szenarien mit hohem Durchsatz und hohen Anforderungen an die Antwortgeschwindigkeit, wie intelligente Kundenservice, Inhaltserstellung, reguläre Chat-Anwendungen usw. Der Preis von nur 0,028 $ pro Million Eingabetoken bei Cache-Treffer senkt die Betriebskosten von groß angelegten Anwendungen erheblich.
Flaggschiff-Leistungserlebnis
Die Version deepseek-v4-pro ist für komplexe Schlussfolgerungs- und Fachaufgaben optimiert und leistet bessere Dienste in Szenarien wie mathematische Berechnungen, Codegenerierung und Fachwissen-Fragen, geeignet für professionelle Anwendungsszenarien, die hochgenaue Ausgaben erfordern.
Unterstützung für ultralangen Kontext
Beide Versionen unterstützen einen ultralangen Kontext von 1 Million Token und eine maximale Ausgabelänge von 384.000 Token und können sehr große Textaufgaben wie ganze Bücher, lange Dokumente und vollständigen Projektcode verarbeiten, was eine starke Grundlage für die Entwicklung komplexer KI-Anwendungen bietet.
Schnellstartanleitung
Der Einstieg in DeepSeek V4 ist sehr einfach:
- Besuchen Sie die offizielle DeepSeek-Website, um ein Konto zu registrieren
- Holen Sie sich den API-Schlüssel
- Führen Sie Schnittstellenaufrufe gemäß der offiziellen Dokumentation durch
- Beginnen Sie mit dem Aufbau Ihrer KI-Anwendung
Die Veröffentlichung von DeepSeek V4 bietet Entwicklern mehr Auswahlmöglichkeiten. Egal, ob Sie ein individueller Entwickler oder eine Unternehmensanwendung sind, Sie können in diesem Modellsystem eine Rechenleistungslösung finden, die Ihren Anforderungen entspricht. Mit der kontinuierlichen Verbesserung des Modellökosystems gehen wir davon aus, dass DeepSeek V4 zu einem wichtigen Eckpfeiler für die Entwicklung von KI-Anwendungen werden und die Geburt von mehr innovativen Produkten fördern wird.