DeepSeek V4 officiellement lancé, tarifs API officiels annoncés
Mots clés: deepseek v4, site officiel deepseek, tutoriel deepseek, prix deepseek v4
Date de publication: 25 avril 2026
Auteur: DeepSeek HK
Aujourd’hui, DeepSeek a officiellement annoncé le plan de tarification API pour les nouveaux modèles de la gamme V4, marquant le lancement commercial officiel de ce grand modèle nouvelle génération très attendu pour les développeurs du monde entier. La gamme DeepSeek V4 comprend deux versions: Flash et Pro, toutes deux prennent en charge un contexte ultra-long de 1 million de tokens. Alors que les performances ont été considérablement améliorées, l’efficacité des coûts a également été optimisée, offrant une option plus compétitive pour le développement d’applications d’IA.
Description du modèle et tarification
Les tarifs API DeepSeek sont calculés par million de tokens. Un token est la plus petite unité de texte reconnue par le modèle, qui peut être un mot, un nombre ou même un signe de ponctuation. Les frais sont calculés en fonction du nombre total de tokens d’entrée et de sortie réellement traités par le modèle.
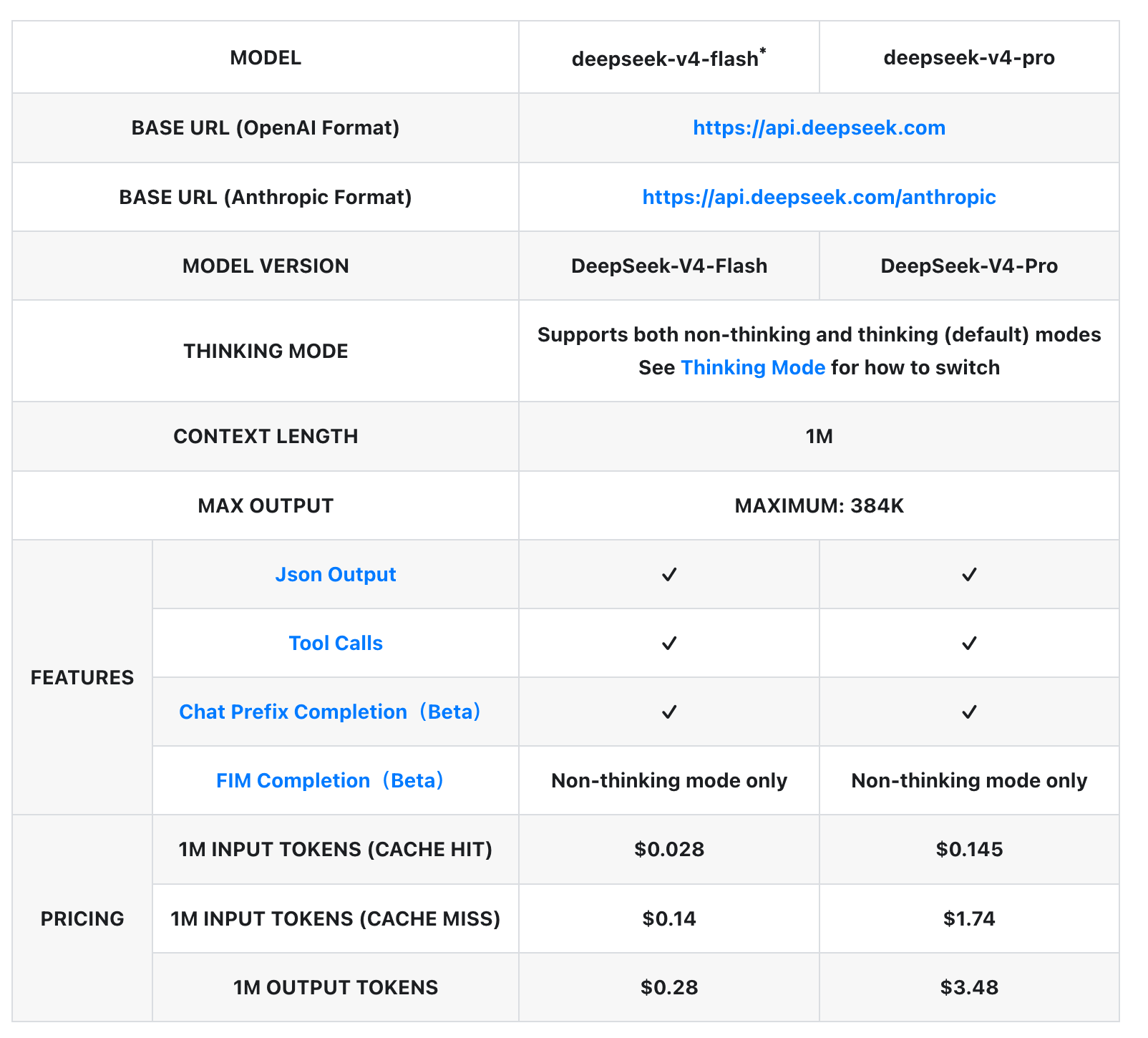
Comparaison détaillée des paramètres du modèle
| Caractéristique | deepseek-v4-flash* | deepseek-v4-pro |
|---|---|---|
| URL de base (format OpenAI) | https://api.deepseek.com | https://api.deepseek.com |
| URL de base (format Anthropic) | https://api.deepseek.com/anthropic | https://api.deepseek.com/anthropic |
| Version du modèle | DeepSeek-V4-Flash | DeepSeek-V4-Pro |
| Mode de réflexion | Prend en charge à la fois le mode sans réflexion et le mode de réflexion (par défaut). Consultez le mode de réflexion pour les instructions de changement | Prend en charge à la fois le mode sans réflexion et le mode de réflexion (par défaut). Consultez le mode de réflexion pour les instructions de changement |
| Longueur de contexte | 1 million | 1 million |
| Longueur maximale de sortie | Jusqu’à 384 000 | Jusqu’à 384 000 |
| Sortie JSON | ✓ | ✓ |
| Appels d’outils | ✓ | ✓ |
| Complétion de préfixe de chat (Bêta) | ✓ | ✓ |
| Complétion FIM (Bêta) | Mode sans réflexion uniquement | Mode sans réflexion uniquement |
| 1 million de tokens d’entrée (succès de cache) | 0,028 $ | 0,145 $ |
| 1 million de tokens d’entrée (échec de cache) | 0,14 $ | 1,74 $ |
| 1 million de tokens de sortie | 0,28 $ | 3,48 $ |
- Remarque: Les noms de modèles « deepseek-chat » et « deepseek-reasoner » seront progressivement abandonnés à l’avenir. Pour la compatibilité, ces deux noms correspondent actuellement respectivement au mode sans réflexion et au mode de réflexion de « deepseek-v4-flash ».
Règles de déduction des frais
Montant de consommation réel = utilisation de tokens × prix unitaire correspondant. Les frais sont déduits directement de votre solde de recharge ou de votre solde de cadeau. Lorsque les deux soldes existent, le système priorise l’utilisation du solde de cadeau.
Les prix des produits peuvent être ajustés en fonction des conditions du marché, et DeepSeek se réserve le droit final d’ajustement des prix. Il est recommandé aux développeurs de recharger en fonction de leurs besoins d’utilisation réels et de consulter régulièrement la page de prix officielle pour obtenir les informations les plus récentes.
Analyse des avantages clés
Tout en maintenant une haute performance, la gamme DeepSeek V4 applique une stratégie de tarification extrêmement compétitive, particulièrement adaptée aux différents scénarios d’applications d’IA:
Option de puissance de calcul rentable
La version deepseek-v4-flash offre des performances excellentes à un prix extrêmement bas, particulièrement adaptée aux scénarios à haut débit et à exigences élevées de vitesse de réponse, comme le service client intelligent, la génération de contenu, les applications de chat régulières, etc. Son prix de seulement 0,028 $ par million de tokens d’entrée en cas de succès de cache réduit considérablement les coûts d’exploitation des applications à grande échelle.
Expérience de performance de gamme
La version deepseek-v4-pro est optimisée pour les tâches de raisonnement complexes et les domaines professionnels, et offre de meilleures performances dans des scénarios comme les calculs mathématiques, la génération de code, les questions de connaissances professionnelles, adaptée aux scénarios d’applications professionnelles qui nécessitent des sorties de haute précision.
Prise en charge de contexte ultra-long
Les deux versions prennent en charge un contexte ultra-long de 1 million de tokens et une longueur de sortie maximale de 384 000 tokens, et peuvent traiter des tâches de texte de très grande taille comme des livres complets, des documents longs et du code de projet complet, offrant une base solide pour le développement d’applications d’IA complexes.
Guide de démarrage rapide
Commencer à utiliser DeepSeek V4 est très simple:
- Visitez le site officiel de DeepSeek pour enregistrer un compte
- Obtenez la clé API
- Effectuez des appels d’interface conformément à la documentation officielle
- Commencez à construire votre application d’IA
La publication de DeepSeek V4 offre plus d’options aux développeurs. Que vous soyez un développeur individuel ou une application de niveau entreprise, vous pouvez trouver une solution de puissance de calcul adaptée à vos besoins dans ce système de modèles. Avec l’amélioration continue de l’écosystème de modèles, nous pensons que DeepSeek V4 deviendra une pierre angulaire importante pour le développement d’applications d’IA, favorisant la naissance de plus de produits innovants.