DeepSeek V4 ufficialmente lanciato, prezzi API ufficiali annunciati
Parole chiave: deepseek v4, sito ufficiale deepseek, tutorial deepseek, prezzo deepseek v4
Data di pubblicazione: 25 aprile 2026
Autore: DeepSeek HK
Oggi, DeepSeek ha annunciato ufficialmente il piano di prezzi API per i nuovi modelli della serie V4, che segna il lancio commerciale ufficiale di questo atteso modello grande di prossima generazione per gli sviluppatori di tutto il mondo. La serie DeepSeek V4 include due versioni: Flash e Pro, entrambe supportano un contesto ultralungo di 1 milione di token. Mentre il livello di prestazione è stato notevolmente migliorato, anche l’efficienza dei costi è stata ottimizzata, offrendo un’opzione più competitiva per lo sviluppo di applicazioni IA.
Descrizione del modello e prezzi
I prezzi delle API DeepSeek sono calcolati per milione di token. Un token è la più piccola unità di testo riconosciuta dal modello, che può essere una parola, un numero o anche un segno di punteggiatura. Le tariffe sono calcolate in base al numero totale di token di input e output effettivamente elaborati dal modello.
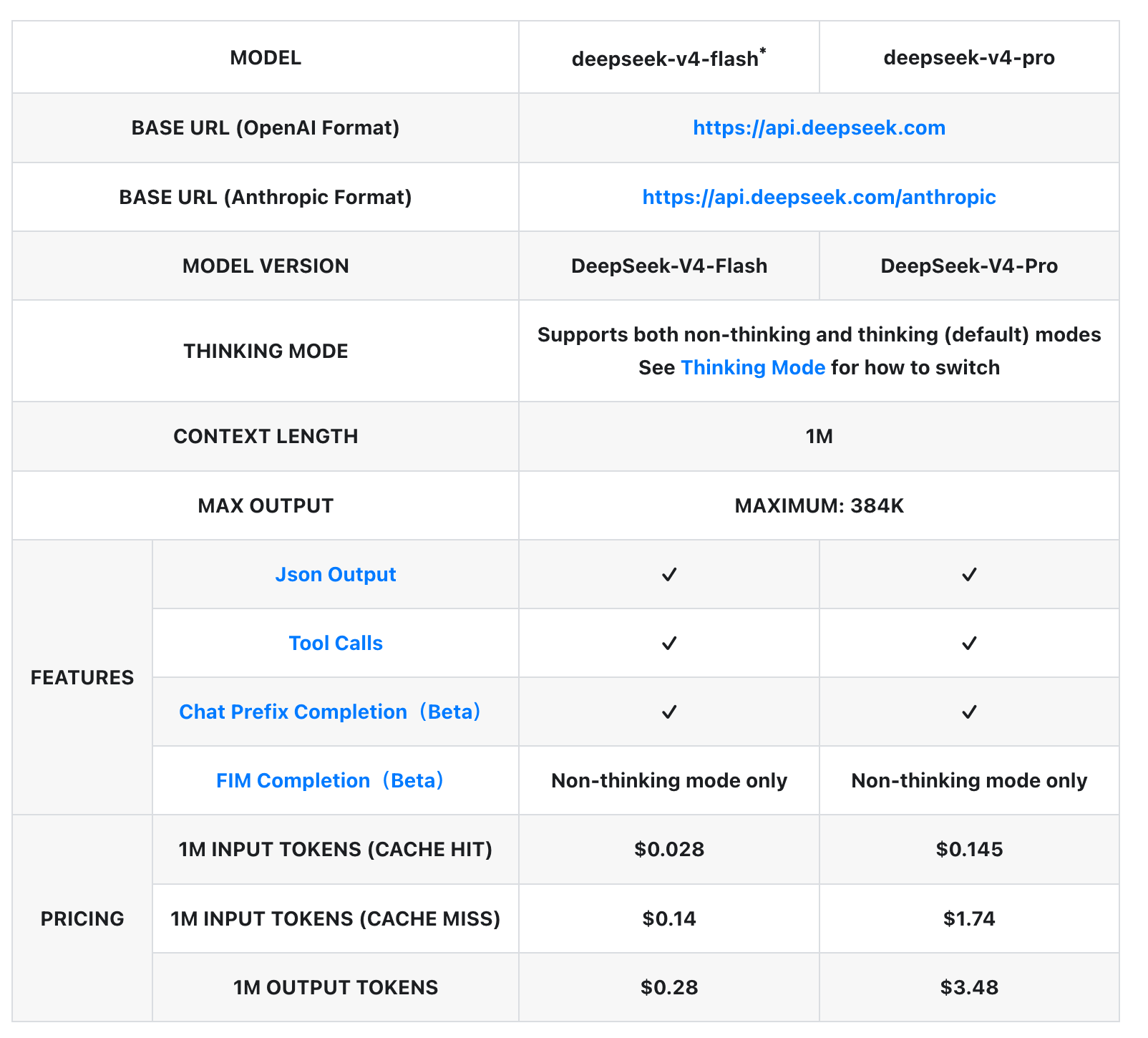
Confronto dettagliato dei parametri del modello
| Caratteristica | deepseek-v4-flash* | deepseek-v4-pro |
|---|---|---|
| URL base (formato OpenAI) | https://api.deepseek.com | https://api.deepseek.com |
| URL base (formato Anthropic) | https://api.deepseek.com/anthropic | https://api.deepseek.com/anthropic |
| Versione modello | DeepSeek-V4-Flash | DeepSeek-V4-Pro |
| Modalità di pensiero | Supporta sia la modalità non pensante che quella di pensiero (predefinita). Consultare la modalità di pensiero per le istruzioni di cambio | Supporta sia la modalità non pensante che quella di pensiero (predefinita). Consultare la modalità di pensiero per le istruzioni di cambio |
| Lunghezza contesto | 1 milione | 1 milione |
| Lunghezza massima di uscita | Fino a 384 mila | Fino a 384 mila |
| Uscita JSON | ✓ | ✓ |
| Chiamate di strumenti | ✓ | ✓ |
| Completamento prefisso chat (Beta) | ✓ | ✓ |
| Completamento FIM (Beta) | Solo modalità non pensante | Solo modalità non pensante |
| 1 milione di token di input (hit cache) | $0,028 | $0,145 |
| 1 milione di token di input (miss cache) | $0,14 | $1,74 |
| 1 milione di token di uscita | $0,28 | $3,48 |
- Nota: I nomi dei modelli “deepseek-chat” e “deepseek-reasoner” verranno gradualmente eliminati in futuro. Per compatibilità, questi due nomi corrispondono attualmente rispettivamente alla modalità non pensante e alla modalità di pensiero di “deepseek-v4-flash”.
Regole di detrazione delle tariffe
Importo di consumo effettivo = utilizzo di token × prezzo unitario corrispondente. Le tariffe verranno detratte direttamente dal saldo di ricarica o dal saldo regalo. Quando esistono entrambi i saldi, il sistema darà la priorità all’uso del saldo regalo.
I prezzi dei prodotti possono essere adattati in base alle condizioni di mercato e DeepSeek si riserva il diritto finale di adattamento dei prezzi. Si consiglia agli sviluppatori di ricaricare in base alle reali esigenze di utilizzo e di controllare regolarmente la pagina dei prezzi ufficiale per ottenere le informazioni più recenti.
Analisi dei vantaggi chiave
Pur mantenendo alte prestazioni, la serie DeepSeek V4 applica una strategia di prezzi estremamente competitiva, particolarmente adatta a vari scenari di applicazioni IA:
Opzione di potenza di calcolo conveniente
La versione deepseek-v4-flash offre prestazioni eccellenti a un prezzo estremamente basso, particolarmente adatta a scenari con alto throughput e alti requisiti di velocità di risposta, come servizio clienti intelligente, generazione di contenuti, applicazioni di chat regolari, ecc. Il suo prezzo di soli $0,028 per milione di token di input in caso di hit della cache riduce significativamente i costi operativi delle applicazioni su larga scala.
Esperienza di prestazioni di punta
La versione deepseek-v4-pro è ottimizzata per attività di ragionamento complesse e campi professionali e ha prestazioni migliori in scenari come calcoli matematici, generazione di codice, domande di conoscenza professionale, adatta a scenari di applicazioni professionali che richiedono output ad alta precisione.
Supporto di contesto ultralungo
Entrambe le versioni supportano un contesto ultralungo di 1 milione di token e una lunghezza massima di uscita di 384 mila token, e possono gestire attività di testo di dimensioni molto grandi come libri completi, documenti lunghi, codice di progetto completo, fornendo una base solida per lo sviluppo di applicazioni IA complesse.
Guida di avvio rapido
Iniziare a usare DeepSeek V4 è molto semplice:
- Visita il sito ufficiale di DeepSeek per registrare un account
- Ottieni la chiave API
- Esegui le chiamate dell’interfaccia secondo la documentazione ufficiale
- Inizia a costruire la tua applicazione IA
Il lancio di DeepSeek V4 offre più opzioni agli sviluppatori. Sia tu uno sviluppatore individuale o un’applicazione a livello aziendale, puoi trovare una soluzione di potenza di calcolo adatta alle tue esigenze in questo sistema di modelli. Con il miglioramento continuo dell’ecosistema dei modelli, crediamo che DeepSeek V4 diventerà una pietra angolare importante per lo sviluppo delle applicazioni IA, promuovendo la nascita di più prodotti innovativi.