DeepSeek V4 chockerar branschen: Dess betydelse går långt utöver prisvärdhet
Denna artikel fokuserar på DeepSeek V4:s tekniska genombrott, prestanda och branschbetydelse, och ger en heltäckande analys av det nya storskaliga modellens kärnvärde. Innehållet är lätt att förstå och lämpligt för teknikentusiaster, utvecklare och företagsbeslutsfattare.
Nyckelord: deepseek v4, deepseek officiell webbplats, deepseek handledning, deepseek v4 pris.
Lanseringsdatum: 2026-04-25 Författare: DeepSeek HK
1. En eras tröskel har försvunnit idag
DeepSeek V4 lanseras officiellt, med samtidig öppen källkod. När jag såg denna nyhet skickade jag den omedelbart till teknikteamet: integrera den nu. Detta är inte blint trendföljande. Efter att noggrant ha granskat lanseringsdatan insåg jag tydligt att den sista tröskeln för AI-implementering har brutits helt idag.
För företag och utvecklare är detta inte bara lanseringen av ännu en ny modell, utan en stor vändpunkt för hela AI-applikationsekosystemet.
2. 1M kontext, inte längre ett privilegium
Miljon-token lång kontext har länge varit standard på slutna modeller som Claude, GPT-4.1 och Gemini, men DeepSeek:s föregående generation V3 var fast vid 128k. Denna gång hoppar V4 direkt till 1 miljon, vilket innebär att du kan lägga in flera års kontraktsdokument för ett företag, alla mötesprotokoll för ett projekt och en hel kvartals operativa data på en gång, låta den förstå hela sammanhanget innan den svarar, och eliminera behovet av krånglig uppdelning och hopplappning.
Ännu viktigare är hur den uppnår detta: genom att designa om den underliggande uppmärksamhetsmekanismen, när den bearbetar 1 miljon token-scenarier, är inferensberäkningen endast 27% av föregående generation, och minnesanvändningen minskas till 10%. Det som tidigare krävde stapling av beräkningskraft kan nu uppnås med betydligt färre resurser. Miljonnivåkontext har äntligen utvecklats från en “lyx” till en “allmänning”.
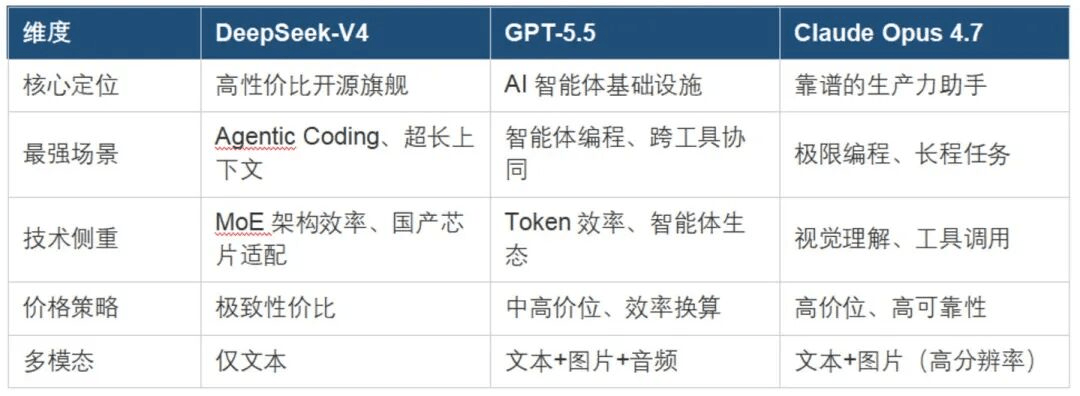
3. Programmeringsförmåga står för första gången på den högsta scenen
Framväxten av DeepSeek V4-Pro markerar första gången en öppen källkodsmodell verkligen har kommit ikapp programmeringsförmågan hos de främsta slutna modellerna.
Guldstandarden för att mäta AI-programmeringsförmåga är SWE-bench-testet, som kräver att modeller åtgärdar verkliga kodfel, närmast programmerares faktiska arbetsplats, och svårt att förbättra genom att borsta poäng. De senaste testresultaten visar:
- Claude Opus 4.7 får 87,6%
- GPT-5.5 får 82,7%
- DeepSeek V4-Pro kommer också in i samma prestandaspann
Internt på DeepSeek hade mer än 50 ingenjörer använt V4-Pro för att hantera verkliga programmeringsuppgifter, och 52% anser att den redan kan användas som deras primära utvecklingsverktyg. Vikten av frasen “kan användas som primärt verktyg” förstås bäst av programmerare. Detta är första gången en öppen källkodsmodell har klivit upp på denna scen och verkligen tävlar på lika villkor med de främsta slutna modellerna.
4. Kostnadströskeln för att använda AI har helt försvunnit
Pris är DeepSeek V4:s mest slående fördel. Per miljon tokens output:
- DeepSeek V4-Pro kostar 3,48 USD
- Claude Opus 4.7 kostar 25 USD
- GPT-5.5 kostar 30 USD
Prisskillnaden når 7 till 9 gånger. Kombinerat med effektivitetsförbättringarna som nämndes tidigare, i 1 miljon token lång kontext-scenarier, är DeepSeek V4-Pro:s faktiska användningskostnad endast 27% av föregående generation. Det är så här billigt inte på grund av vinstkompression, utan för att den omdesignade underliggande arkitekturen medför väsentliga effektivitetsförbättringar.
Vad betyder detta för företag? De scenarier som tidigare var “för mycket data för att bearbeta överkomligt” eller “långdokumentanalys är för dyr”, de AI-applikationer som placerades på “vi gör det senare”-listan, blir alla “kan göras nu” idag. Kostnadströskeln för AI-implementering har helt raderats ut.
5. Kinesisk AI, tävlar rakt på
Det finns en sak till som är viktigare än själva teknikdatan. DeepSeek V4 valde att lansera samma dag som GPT-5.5:s lansering, och tävlar rakt på utan tvekan. Den körs helt på Huaweis chip, använder Apache 2.0 öppen källkodslicens, och är tillgänglig globalt.
En uppsättning data illustrerar bäst situationen:
- I maj 2023 var prestationsgapet mellan toppkinesiska och amerikanska modeller 31,6 procentenheter
- I mars 2026 har detta gap minskat till 2,7%
Under denna period var privat AI-investering i USA 23 gånger den i Kina. DeepSeek använde algoritmisk asymmetri för att motverka beräkningskraftasymmetri, och uppnådde verkligen lika konkurrens och rakt på utmaning.
6. Detta är bara början, den verkliga skillnaden ligger i applikationsskiktet
Att ha den bästa motorn räcker inte — du behöver fortfarande en bil som kan köra. Oavsett hur kraftfull motorn är kan den inte transportera gods från punkt A till punkt B av sig själv. Vad företag verkligen behöver är en praktisk AI-lösning: någon ansvarig för innehållsproduktion, någon för dataanalys, någon för driftsexekvering, någon för kodutveckling och systeminspektion, var och en utför sina plikter, arbetar 24/7 utan avbrott.
Ju starkare DeepSeek V4 är, desto högre blir kapacitetstaket för detta AI-system; ju billigare den är, desto lägre blir tröskeln för företag att bygga detta system. Topp-AI-kapaciteter blir en allmän infrastruktur. Den verkliga skillnaden i framtiden ligger i hur du integrerar den i din verksamhet, bygger den, kör den, hur djupt du använder den, och hur snabbt du rör dig.
Om du vill uppleva DeepSeek V4:s kraftfulla kapacheter förstahands, välkommen att använda den direkt via vår plattform.