DeepSeek V4震撼亮相, 它的意义绝不只是便宜
本文围绕DeepSeek V4的技术突破、性能表现和行业意义展开,全面解析这款新一代大模型的核心价值,内容通俗易懂,适合技术爱好者、开发者和企业决策者参考。
关键词:deepseek v4、deepseek 官网、deepseek教程、deepseek v4价格。
发布日期:2026-04-25 作者:DeepSeek HK
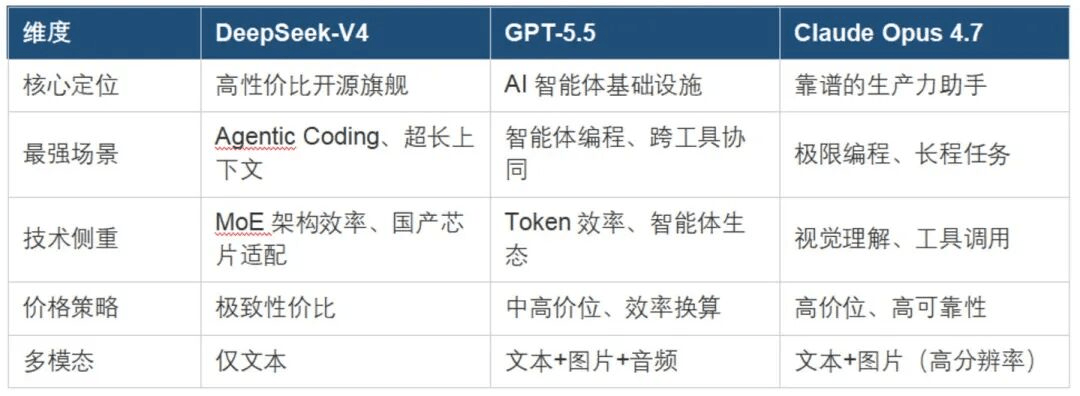
一、一个时代的门槛,今天消失了
DeepSeek V4正式发布了,同步开源。看到这个消息的时候,我第一时间发给技术团队:立即接入。这不是盲目追热点,而是仔细看完发布数据之后,我清楚地意识到:AI落地的最后一道门槛,今天被彻底打破了。
对于企业和开发者来说,这不仅仅是又一款新模型的发布,更是整个AI应用生态的一次重大拐点。
二、1M上下文,终于不再是特权
百万token长上下文,在Claude、GPT-4.1、Gemini等闭源模型上早已成为标配,但DeepSeek上一代V3还停留在128k。这次V4直接跃升到100万,相当于可以把一家公司几年的合同文档、一个项目所有的会议记录、整个季度的运营数据,一次性全部丢进去,让它整体理解之后再回答,再也不需要麻烦的切片拼凑。
更重要的是它实现的方式:通过重新设计底层注意力机制,处理100万token的场景时,推理计算量只有前代的27%,显存占用更是降到了10%。以前靠堆算力才能做到的事情,现在用少得多的资源就能实现,百万级上下文终于从”奢侈品”变成了”普惠品”。
三、编程能力首次站上顶尖擂台
DeepSeek V4-Pro的出现,标志着开源模型第一次在编程能力上真正追上了顶尖闭源模型的脚步。
衡量AI编程能力的黄金标准是SWE-bench测试,它要求模型自己去修复真实世界的代码bug,最接近程序员的实际工作场景,很难靠刷分提升。最新的测试结果显示:
- Claude Opus 4.7得分87.6%
- GPT-5.5得分82.7%
- DeepSeek V4-Pro也进入了同一个水平区间
DeepSeek内部让50多位工程师用V4-Pro处理真实编程任务,52%的人认为它已经可以作为主力开发工具。“可以当主力”这几个字的分量,程序员群体最能体会。这是开源模型第一次站上这个台阶,真正和顶级闭源模型同台竞技。
四、用AI的费用门槛彻底消失了
价格是DeepSeek V4最具冲击力的优势。每百万token输出:
- DeepSeek V4-Pro是$3.48
- Claude Opus 4.7是$25
- GPT-5.5是$30
价格差距达到了7到9倍。结合前面提到的效率提升,在100万token长上下文场景下,DeepSeek V4-Pro的实际使用成本只有前代的27%。它变得这么便宜,不是靠压缩利润,而是因为底层架构的重新设计带来了本质的效率提升。
这对企业意味着什么?以前那些”数据量太大处理不起”、“长文档分析成本太高”的场景,以前放在”以后再说”清单里的AI应用,今天全部变成了”现在就能做”。AI落地的成本门槛,就这样被彻底抹平了。
五、国产AI,正面亮剑
还有一件事,比技术数据本身更重要。DeepSeek V4选择在GPT-5.5发布的同一天亮相,正面竞争,毫不回避。它完全跑在华为芯片上,采用Apache 2.0开源协议,全球可用。
有一组数据最能说明问题:
- 2023年5月,中美顶尖模型的性能差距是31.6个百分点
- 2026年3月,这个差距已经压缩到了2.7%
而在这期间,美国私人AI投资是中国的23倍。DeepSeek用算法的不对称,抵消了算力的不对称,真正做到了同台竞技,正面亮剑。
六、这只是开始,真正的差距在应用层
有了最好的发动机,还需要一辆能跑的车。发动机再强,它自己不会把货物从A地运到B地。企业真正需要的,是一套能实际干活的AI解决方案:有人负责内容生产,有人负责数据分析,有人负责运营执行,有人负责代码开发和系统巡检,各司其职,7×24小时不间断工作。
DeepSeek V4越强,这套AI系统的能力上限就越高;越便宜,企业搭建这套系统的门槛就越低。顶尖AI能力正在变成一种公共基础设施,未来真正的差距,在于你怎么把它用进你的业务里,建起来,跑起来,用得多深,走得多快。
如果你想第一时间体验DeepSeek V4的强大能力,欢迎通过我们的平台直接使用。