DeepSeek V4 шокує галузь: його значення значно виходить за рамки доступності
Ця стаття зосереджена на технологічних проривах DeepSeek V4, продуктивності та значенні для галузі, надаючи всебічний аналіз основної цінності цієї нової генерації великої моделі. Зміст легкий для розуміння, підходить для технологічних ентузіастів, розробників та керівників підприємств.
Ключові слова: deepseek v4, deepseek офіційний вебсайт, deepseek підручник, deepseek v4 ціна.
Дата випуску: 2026-04-25 Автор: DeepSeek HK
1. Поріг ери зник сьогодні
DeepSeek V4 офіційно випущено з одночасним відкритим кодом. Коли я побачив цю новину, я негайно надіслав її технічній команді: інтегруйте її зараз. Це не сліпе слідування за трендом. Ретельно переглянувши дані випуску, я чітко усвідомив, що останній поріг для впровадження ШІ сьогодні повністю подолано.
Для підприємств та розробників це не просто випуск чергової нової моделі, а великий поворотний пункт для всієї екосистеми застосунків ШІ.
2. 1M контекст — більше не привілей
Мільйонний довгий контекст вже давно є стандартом для закритих моделей, таких як Claude, GPT-4.1 та Gemini, але попереднє покоління DeepSeek V3 було обмежено 128k. Цього разу V4 стрибає прямо до 1 мільйона, що означає, що ви можете відразу помістити кілька років контрактних документів компанії, усі протоколи зустрічей проєкту та оперативні дані цілого кварталу, дозволити йому зрозуміти весь контекст, перш ніж відповідати, усуваючи потребу у громіздкому нарізанні та склеюванні.
Що ще важливіше, як це досягається: шляхом повторного проєктування базового механізму уваги, при обробці сценаріїв з 1 мільйоном токенів обчислення висновків становлять лише 27% від попереднього покоління, а використання пам’яті зменшується до 10%. Те, що раніше вимагало накопичення обчислювальної потужності, тепер можна досягти з набагато меншими ресурсами. Контекст мільйонного рівня нарешті еволюціонував з “розкоші” до “суспільного блага”.
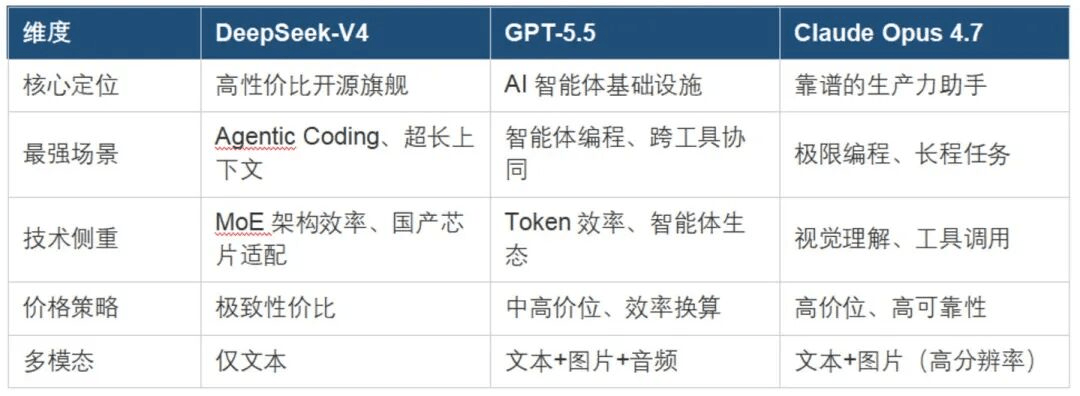
3. Здатність програмування вперше виходить на найвищу сцену
Поява DeepSeek V4-Pro позначає перший випадок, коли модель з відкритим кодом справді наздогнала можливості програмування топових закритих моделей.
Золотим стандартом вимірювання здатності ШІ до програмування є тест SWE-bench, який вимагає від моделей виправлення реальних помилок у коді, найближче до реальних робочих сценаріїв програмістів, і який важко покращити, набираючи бали. Останні результати тестів показують:
- Claude Opus 4.7 набирає 87,6%
- GPT-5.5 набирає 82,7%
- DeepSeek V4-Pro також входить у той же діапазон продуктивності
У DeepSeek внутрішньо понад 50 інженерів використовували V4-Pro для виконання реальних завдань програмування, і 52% вважають, що його вже можна використовувати як основний інструмент розробки. Вагу фрази “можна використовувати як основний інструмент” найкраще розуміють програмісти. Це перший випадок, коли модель з відкритим кодом вийшла на цю сцену, по-справжньому конкуруючи на рівних із топовими закритими моделями.
4. Поріг вартості використання ШІ повністю зник
Ціна є найбільш вражаючою перевагою DeepSeek V4. На мільйон вихідних токенів:
- DeepSeek V4-Pro коштує 3,48$
- Claude Opus 4.7 коштує 25$
- GPT-5.5 коштує 30$
Ціновий розрив сягає від 7 до 9 разів. У поєднанні з покращеннями ефективності, згаданими раніше, у сценаріях довгого контексту в 1 мільйон токенів фактична вартість використання DeepSeek V4-Pro становить лише 27% від попереднього покоління. Це так дешево не через стиснення прибутку, а тому, що повторно спроєктована базова архітектура приносить принципові покращення ефективності.
Що це означає для підприємств? Ті сценарії, які раніше були “надто багато даних для доступної обробки” або “аналіз довгих документів занадто дорогий”, ті застосунки ШІ, які були внесені до списку “зробимо пізніше”, сьогодні стають “можна зробити зараз”. Поріг вартості для впровадження ШІ повністю стертий.
5. Китайський ШІ, пряма конкуренція
Є ще одна річ, важливіша за самі технічні дані. DeepSeek V4 обрав запуск у той самий день, що й випуск GPT-5.5, конкуруючи прямо без вагань. Він повністю працює на чипах Huawei, використовує ліцензію з відкритим кодом Apache 2.0 та доступний глобально.
Один набір даних найкраще ілюструє ситуацію:
- У травні 2023 року розрив у продуктивності між топовими китайськими та американськими моделями становив 31,6 відсоткових пунктів
- У березні 2026 року цей розрив звузився до 2,7%
Протягом цього періоду приватні інвестиції в ШІ в США були в 23 рази більшими, ніж у Китаї. DeepSeek використав алгоритмічну асиметрію для компенсації асиметрії обчислювальної потужності, дійсно досягнувши рівної конкуренції та прямого виклику.
6. Це лише початок, справжній розрив — на рівні застосунків
Мати найкращий двигун недостатньо — вам все одно потрібен автомобіль, який може їхати. Незалежно від того, наскільки потужний двигун, він не може самостійно перевезти вантаж з пункту А в пункт Б. Що підприємствам дійсно потрібно, так це практичне рішення ШІ: хто відповідає за виробництво контенту, хто за аналіз даних, хто за виконання операцій, хто за розробку коду та перевірку систем, кожен виконує свої обов’язки, працюючи цілодобово без перерви.
Чим потужніший DeepSeek V4, тим вищою стає межа можливостей цієї системи ШІ; чим дешевший він є, тим нижчою стає межа для підприємств для побудови цієї системи. Топові можливості ШІ стають суспільною інфраструктурою. Справжній розрив у майбутньому полягає в тому, як ви інтегруєте його у свій бізнес, будуєте, запускаєте, наскільки глибоко використовуєте та наскільки швидко рухаєтеся.
Якщо ви хочете першими відчути потужні можливості DeepSeek V4, ласкаво просимо використовувати його безпосередньо через нашу платформу.