DeepSeek V4 震撼發佈:其意義遠不止於價格便宜
本文聚焦 DeepSeek V4 的技術突破、效能表現與產業意義,全面解析這一代大模型的核心價值。內容淺顯易懂,適合科技愛好者、開發者與企業決策者。
關鍵詞:deepseek v4、deepseek 官網、deepseek 教學、deepseek v4 價格。
發佈日期:2026-04-25 作者:DeepSeek HK
1. 一個時代的門檻,今天消失了
DeepSeek V4 正式發佈,同步開源。看到這條消息時,我第一時間發給技術團隊:立刻接入。這不是盲目追風口。仔細看完發佈數據後,我清楚地意識到,AI 落地的最後一道門檻,今天已經被徹底打破。
對於企業和開發者而言,這不僅僅是一款新模型的發佈,而是整個 AI 應用生態的重大轉折點。
2. 1M 上下文,不再是特權
百萬 token 長上下文,在 Claude、GPT-4.1、Gemini 等閉源模型上早已是標配,但 DeepSeek 上一代 V3 一直卡在 128k。這次 V4 直接躍升到 100 萬,意味著你可以把一家公司幾年的合約文件、一個專案的全部會議記錄、一整個季度的營運數據,全部一次性放進去,讓它先理解全局再回答,省去繁瑣的切片拼湊。
更重要的是,它是怎麼做到的:重新設計底層注意力機制,在處理 100 萬 token 場景時,推理計算量只有上一代的 27%,記憶體佔用降到 10%。以前需要堆算力才能做的事情,現在可以用少得多的資源完成。百萬級上下文,終於從「奢侈品」進化成了「公共品」。
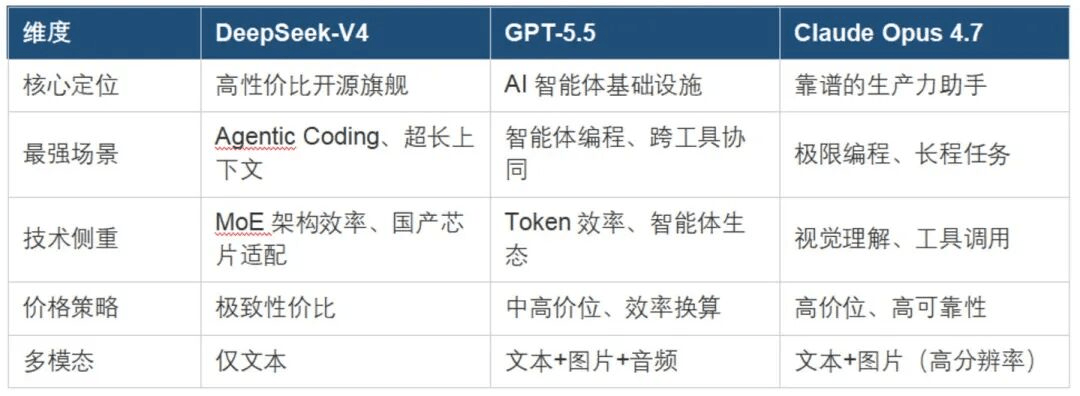
3. 程式設計能力,首次站上頂尖舞台
DeepSeek V4-Pro 的出現,標誌著開源模型首次真正追平了頂尖閉源模型的程式設計能力。
衡量 AI 程式設計能力的黃金標準是 SWE-bench 測試,它要求模型修復真實的程式碼 bug,最接近程式設計師的實際工作場景,也很難靠刷題提分。最新測試結果:
- Claude Opus 4.7 得分 87.6%
- GPT-5.5 得分 82.7%
- DeepSeek V4-Pro 同樣進入同一效能區間
DeepSeek 內部有超過 50 名工程師使用 V4-Pro 處理真實程式設計任務,52% 認為它已經可以作為主要開發工具。這句「可以作為主要工具」的分量,程式設計師最懂。這是開源模型第一次站上這個舞台,真正與頂尖閉源模型同場競技。
4. 使用 AI 的成本門檻,徹底消失
價格是 DeepSeek V4 最震撼的優勢。每百萬 token 輸出:
- DeepSeek V4-Pro 為 3.48 美元
- Claude Opus 4.7 為 25 美元
- GPT-5.5 為 30 美元
價格差距達到 7 至 9 倍。再結合前面提到的效率提升,在 100 萬 token 長上下文場景中,DeepSeek V4-Pro 的實際使用成本只有上一代的 27%。這麼便宜不是因為壓縮利潤,而是重新設計的底層架構帶來的本質效率提升。
這對企業意味著什麼?那些以前「數據太多、處理不起」的場景,那些「長文件分析太貴」的場景,那些被放在「以後再做」清單上的 AI 應用,今天全部變成了「現在就能做」。AI 落地的成本門檻,被徹底抹平。
5. 中國 AI,正面對決
還有一件事,比技術數據本身更重要。DeepSeek V4 選擇在 GPT-5.5 發佈的同一天推出,毫不猶豫地正面對決。它完全運行在華為晶片上,採用 Apache 2.0 開源授權,面向全球開放。
一組數據最能說明問題:
- 2023 年 5 月,中美頂尖模型的效能差距為 31.6 個百分點
- 2026 年 3 月,這個差距已經縮小到 2.7%
在這期間,美國私人 AI 投資是中國的 23 倍。DeepSeek 用演算法不對稱抵消了算力不對稱,真正實現了平等競技、正面挑戰。
6. 這只是開始,真正的差距在應用層
有了最好的引擎還不夠,你還需要一輛能跑的車。引擎再強,也沒辦法自己把貨物從 A 點運到 B 點。企業真正需要的是一個實用的 AI 解決方案:有人負責內容生產,有人負責數據分析,有人負責營運執行,有人負責程式碼開發和系統巡檢,各司其職,24 小時不間斷運作。
DeepSeek V4 越強,這套 AI 系統的能力上限就越高;它越便宜,企業搭建這套系統的門檻就越低。頂尖 AI 能力正在變成公共基礎設施。未來真正的差距,在於你怎麼把它整合進自己的業務、怎麼搭建、怎麼運轉、用得有多深、動作有多快。
如果你想親身體驗 DeepSeek V4 的強大能力,歡迎直接透過我們的平台使用。