GLM-5.2 Intro: Built for Coding and Long-Horizon Tasks
On June 17, 2026, Zhipu AI officially launched and open-sourced its new flagship GLM-5.2. Compared with GLM-5.1, the upgrade is less about one-shot benchmark scores and more about making coding and long-horizon tasks actually work—1M lossless context, stronger engineering execution, MIT license, and Day 0 support on multiple domestic compute platforms.
Keywords: chatgpt, GPT-5.6, gpt tutorial.
Published: June 17, 2026
What GLM-5.2 is for: coding first, finish long jobs
GLM-5.2 targets two high-frequency workflows:
| Scenario | Need | GLM-5.2 response |
|---|---|---|
| Engineering coding | Multi-file edits, debug, tests | Stronger code generation and agent execution |
| Long-horizon tasks | Plan → build → verify across turns | 1M context that holds the whole project |
Zhipu positions GLM-5.2 as a long-horizon flagship: the win is not a single clever answer, but one task running start to delivery without context collapse.
1M context: room for an entire codebase
GLM-5.2 ships a usable 1M-token context (GLM-5.1 was around 200K). That means:
- Mid-size monorepos can be analyzed in one session without constant chunking.
- Docs, implementation, and tests can sit in the same window—fewer “the model forgot what it wrote” moments.
- Long agent loops (plan → code → debug → regression) get a much larger working memory.
In an official stress test, the model delivered a full app spanning web, mobile, and mini-program in one run—about 880K tokens processed, nearly filling the 1M window. Without enough context, humans end up stitching history by hand; throughput drops fast.
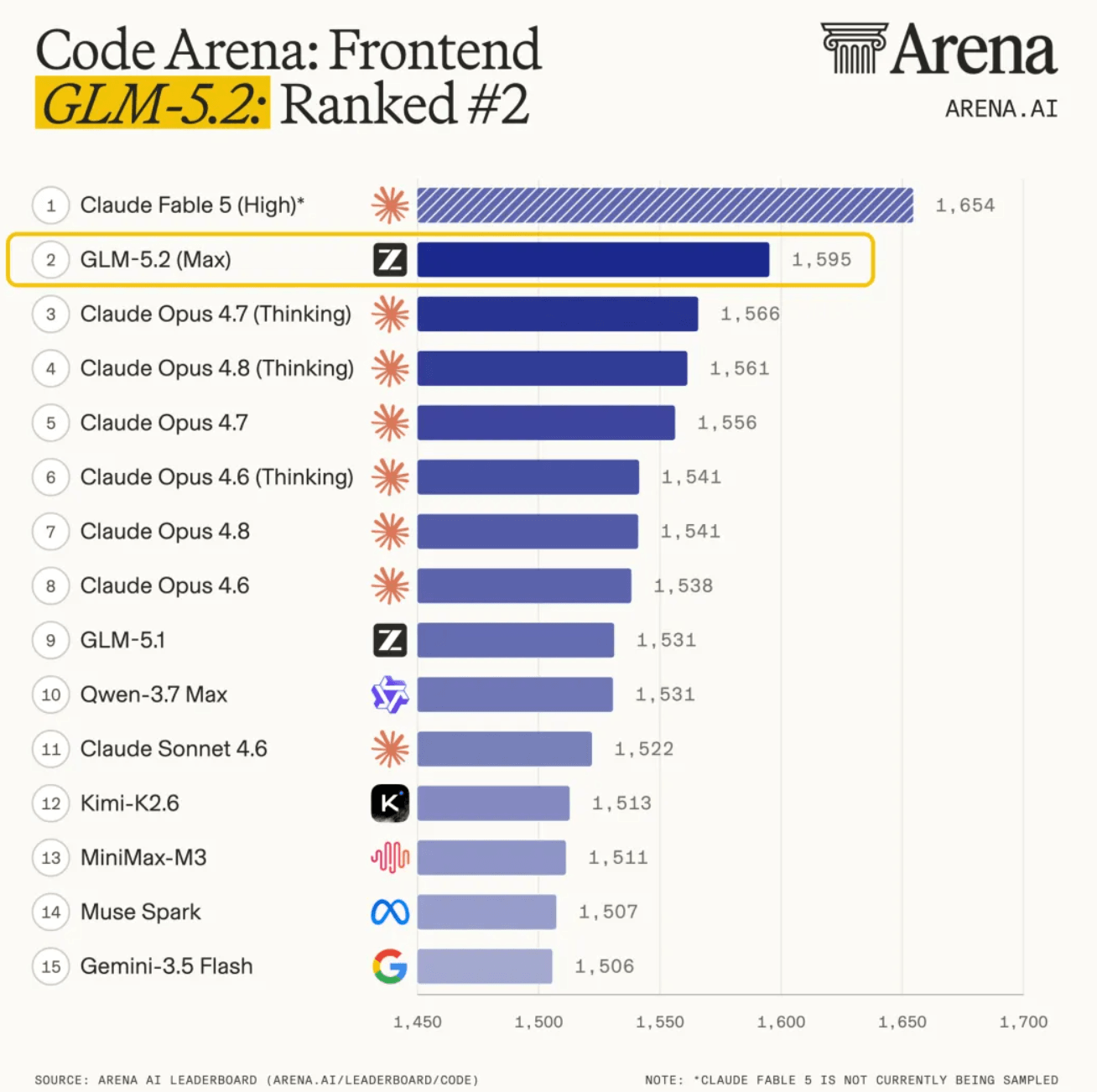
Benchmarks: top open model, closing in on Claude Opus 4.8
On major coding evals, GLM-5.2 ranks as the strongest open-weight model, within single-digit points of closed frontier models:
| Benchmark | GLM-5.2 | Reference |
|---|---|---|
| Code Arena (frontend blind test) | #1 among available models | Millions of user votes |
| FrontierSWE | ~1% behind Claude Opus 4.8 | Ahead of GPT-5.5 |
| Terminal-Bench 2.1 | 81.0 | GLM-5.1 was 63.5 (+17.5) |
| SWE-bench Pro | 62.1 | GLM-5.1 was 58.4 |
The jump from 63.5 to 81.0 on Terminal-Bench is the clearest signal—gains show up in terminal/agent execution, not just static completion.
Architecture: IndexShare and MTP
Two engineering changes matter for builders:
IndexShare (sparse attention): at 1M context, per-token FLOPs drop about 2.9×. Long windows are useless if inference cost explodes; IndexShare makes “1M available” closer to “1M affordable.”
Improved MTP (speculative decoding): acceptance length rises up to 20%, speeding long outputs—especially large code generations.
GLM-5.2 also offers high / max reasoning effort tiers so teams can trade latency for depth, similar to other frontier models.
Open weights, APIs, and domestic compute
GLM-5.2 is MIT-licensed, with weights on Hugging Face and ModelScope—download, deploy, and commercial use allowed. APIs are live on BigModel and Z.ai.
Day 0 inference support includes:
- Huawei Ascend, T-Head, Moore Threads, Cambricon
- Kunlunxin, MetaX, Hygon, Biren
For teams needing on-prem or domestic GPU inference, that matters. GLM Coding Plan users already have access.
GPT tutorial: great coding model—but ChatGPT still runs your day
GLM-5.2 is built for engineering agents; daily drafting, brainstorming, and quick Q&A still flow through ChatGPT. Before GPT-5.6 is everywhere, practice on GPT-5.4 / GPT-5.5:
- Split tasks—goal → subtasks → acceptance criteria, same mindset as agent workflows.
- Manage context—give directory layout and key files before deep edits; don’t waste the window.
- Fixed test prompts—run the same coding asks across models/tiers; log pass rate and latency.
- Compare reasoning tiers—like GLM-5.2 high/max, ChatGPT has fast vs deep modes; learn which fits which job.
Use the button below to open LimaxAI chat (gpt-5.4 today; pick newer models when they appear).
Summary
| Item | Takeaway |
|---|---|
| Focus | Coding + long-horizon flagship |
| Context | 1M tokens for whole projects |
| Benchmarks | Terminal-Bench 81.0; top open model |
| Architecture | IndexShare + MTP speculative decoding |
| License | MIT; Hugging Face / ModelScope |
| Compute | Day 0 on 8 domestic platforms |
| Next step | Practice task splitting in ChatGPT; try GPT on LimaxAI |
GLM-5.2 raises the open coding ceiling again. Whether you run long agents on GLM or keep ChatGPT for daily work, getting task design and context hygiene right beats chasing every new model name.