GLM-5.2 介紹:專注 Coding 與長程任務
6 月 17 日,智譜 AI 正式上線並開源新一代旗艦模型 GLM-5.2。和前代 GLM-5.1 相比,這次升級的核心不是「刷榜分數」,而是把 Coding 能力 和 長程任務 做紮實——1M 無損上下文、更強的工程執行、MIT 開源,Day 0 適配多家國產算力平台。
關鍵字:chatgpt、GPT-5.6、gpt教程。
發布日期:2026年6月17日
GLM-5.2 定位:Coding 優先,長程任務能跑完
GLM-5.2 面向兩類高頻場景:
| 場景 | 具體需求 | GLM-5.2 的應對 |
|---|---|---|
| 工程 Coding | 多檔案改動、除錯、跑測試 | 強化程式生成與 Agent 執行 |
| 長程任務 | 跨多輪規劃、實作、驗收 | 1M 上下文穩定承載完整工程 |
官方把 GLM-5.2 定義為「長程任務旗艦」:不是單次問答更強,而是 一個任務從開始到交付,上下文不斷檔。
1M 上下文:能裝下整個軟體工程
GLM-5.2 實現了真正可用的 1M token 上下文(前代 GLM-5.1 約 200K)。這意味著:
- 中大型 monorepo 可以在 單次對話 裡完成分析,不必頻繁切分檔案。
- 文件 + 實作 + 測試用例可以同時放進上下文,減少「模型忘了前面寫了什麼」的問題。
- 長程 Agent 工作流(規劃 → 編碼 → 除錯 → 回歸)有更大的「工作記憶」。
官方實測案例:模型一次性交付覆蓋 Web、行動端與小程序 的完整應用,累計處理約 88 萬 tokens,幾乎用滿 1M 視窗。
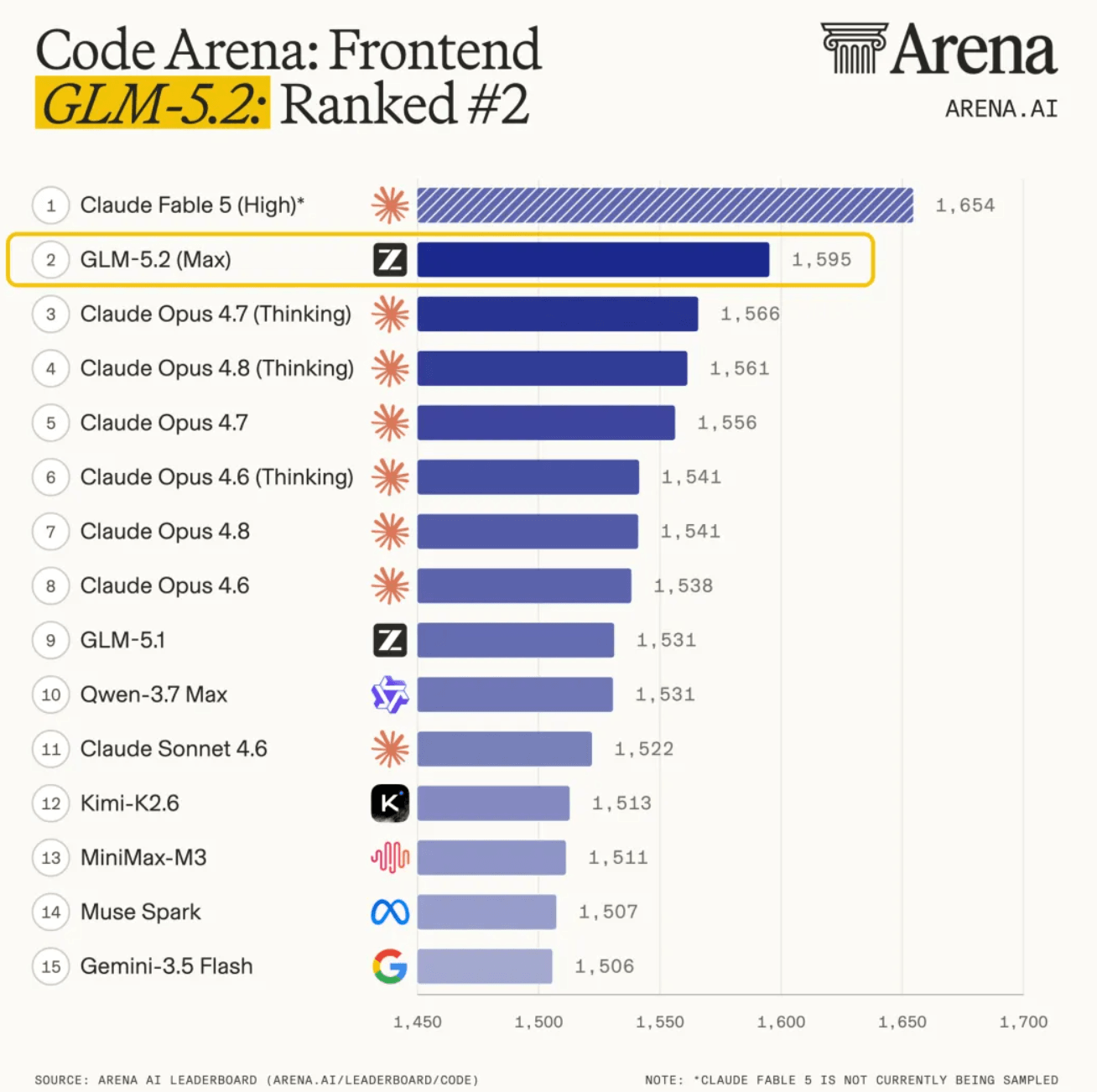
評測表現:開源第一,逼近 Claude Opus 4.8
在多個權威 Coding 評測裡,GLM-5.2 是目前 排名最高的開源模型:
| 評測 | GLM-5.2 | 對比參考 |
|---|---|---|
| Code Arena(前端盲測) | 全球可用模型第一 | 百萬用戶參與 |
| FrontierSWE | 僅比 Claude Opus 4.8 低約 1% | 超過 GPT-5.5 |
| Terminal-Bench 2.1 | 81.0 | GLM-5.1 為 63.5(+17.5) |
| SWE-bench Pro | 62.1 | GLM-5.1 為 58.4 |
Terminal-Bench 從 63.5 跳到 81.0,是這次升級最直觀的數據——說明模型在 終端/Agent 執行 類任務上進步明顯。
架構升級:IndexShare 與 MTP
GLM-5.2 在架構上做了兩項關鍵優化:
IndexShare(稀疏注意力優化):在 1M 上下文長度下,每 token 計算量降低約 2.9 倍。
MTP 層改進(推測解碼):多 token 預測層的接受長度提升最高約 20%。
此外,GLM-5.2 提供 high / max 兩檔推理強度,開發者可以在「速度」和「深度思考」之間切換。
開源、API 與國產算力適配
GLM-5.2 採用 MIT 協議 開源,權重已上線 Hugging Face 與 ModelScope。API 同步上線 BigModel 開放平台與 Z.ai。
線上推理 Day 0 完成與華為昇騰、平頭哥、摩爾執行緒、寒武紀、崑崙芯、沐曦、海光、壁仞等國產算力平台適配。模型也已向 GLM Coding Plan 全量用戶開放。
GPT 教程:Coding 模型很強,日常仍離不開 ChatGPT
GLM-5.2 專攻工程與長程 Agent,但日常寫文件、腦力激盪、快速問答,ChatGPT 仍是最高頻入口。在 GPT-5.6 全面開放前,建議先用 GPT-5.4 / GPT-5.5 練這幾件事:
- 任務拆步:長程 Coding 前先列「目標 → 子任務 → 驗收標準」。
- 上下文管理:大專案先給目錄結構和關鍵檔案清單,再讓模型深入。
- 固定測試樣本:同一組 Coding 提示在不同模型/檔位各跑一遍。
- 推理檔位對照:類似 GLM-5.2 的 high/max,ChatGPT 也有不同 reasoning 檔位。
想先在瀏覽器體驗 GPT,可點下方按鈕進入 LimaxAI(目前 gpt-5.4)。
小結
| 項目 | 要點 |
|---|---|
| 定位 | Coding + 長程任務旗艦 |
| 上下文 | 1M token,可承載完整工程 |
| 評測 | Terminal-Bench 81.0;開源模型第一 |
| 架構 | IndexShare + MTP 推測解碼 |
| 開源 | MIT;Hugging Face / ModelScope |
| 算力 | Day 0 適配 8 家國產平台 |
| 你的下一步 | 用 ChatGPT 練任務拆分與提示,再在 LimaxAI 體驗 GPT |
GLM-5.2 把開源 Coding 模型的天花板又抬高了一檔。無論你用它跑長程 Agent,還是繼續用 ChatGPT 處理日常協作,先把「任務怎麼拆、上下文怎麼管」練熟,比追每一個新模型名更實在。