GLM-5.2: Coding i zadania długoterminowe
17 czerwca 2026 r. Zhipu AI oficjalnie uruchomiła i open-source flagowiec GLM-5.2—fokus na coding i długich zadaniach: kontekst 1M, MIT, Day 0 na krajowych GPU.
Słowa kluczowe: chatgpt, GPT-5.6, samouczek gpt.
Opublikowano: 17 czerwca 2026
GLM-5.2: coding najpierw, dokończyć długie zadania
Dwa częste scenariusze:
| Scenariusz | Potrzeba | GLM-5.2 |
|---|---|---|
| Coding inżynieryjny | Multi-plik, debug, testy | Generacja kodu + agent |
| Długie zadania | Plan → build → verify | Kontekst 1M dla całego projektu |
Zadanie od startu do dostawy bez kolapsu kontekstu.
Kontekst 1M: miejsce na całą codebase
1M tokenów (GLM-5.1 200K). Średnie monorepo w jednej sesji. Test oficjalny: web, mobile, mini-program—880K tokenów.
Benchmarki: top open, blisko Claude Opus 4.8
GLM-5.2 = najsilniejszy model open na coding evals:
| Bench | GLM-5.2 | Odniesienie |
|---|---|---|
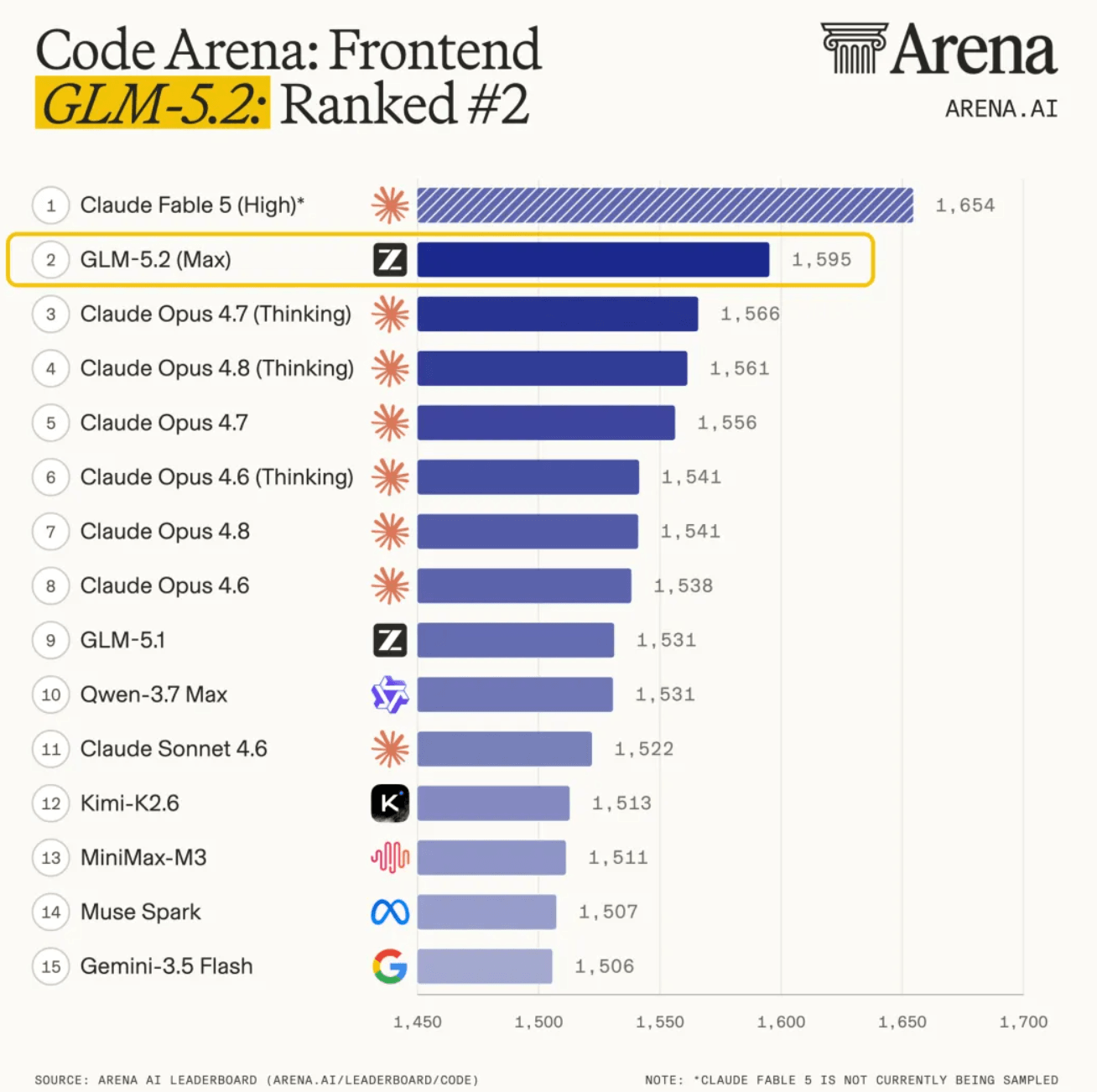
| Code Arena (frontend) | #1 dostępne modele | Miliony głosów |
| FrontierSWE | ~1% za Opus 4.8 | Przed GPT-5.5 |
| Terminal-Bench 2.1 | 81.0 | GLM-5.1 63.5 (+17.5) |
| SWE-bench Pro | 62.1 | GLM-5.1 58.4 |
63.5 → 81.0 na Terminal-Bench = terminal/agent execution.
Architektura: IndexShare i MTP
IndexShare: FLOPs ~2.9× mniej przy 1M. MTP: do 20% acceptance. Poziomy high/max.
Open weights, API, krajowy compute
Licencja MIT; Hugging Face/ModelScope. API BigModel i Z.ai. Day 0: Ascend, T-Head, Moore Threads, Cambricon, Kunlunxin, MetaX, Hygon, Biren.
Samouczek GPT: mocny coding, ChatGPT na co dzień
GLM-5.2 dla agentów; ChatGPT na daily drafts. Przed GPT-5.6 na GPT-5.4/5.5:
- Dziel zadania
- Zarządzaj kontekstem
- Stałe test prompts
- Porównuj reasoning tiers
Przycisk LimaxAI (gpt-5.4).
Podsumowanie
| Element | Wniosek |
|---|---|
| Fokus | Coding + long horizon |
| Kontekst | 1M tokenów |
| Bench | Terminal-Bench 81.0 |
| Architektura | IndexShare + MTP |
| Licencja | MIT |
| Compute | 8 platform Day 0 |
| Dalej | ChatGPT + LimaxAI |
GLM-5.2 podnosi sufit open coding. Najpierw opanuj design zadań w ChatGPT.